 인공지능 데이터 품질 개념/자료=과기정통부
인공지능 데이터 품질 개념/자료=과기정통부과학기술정보통신부(이하 과기정통부)는 오는 6일 한국정보통신기술협회 내의 단체 표준화 기구(TTA PG 1005, 인공지능기반기술)에 이번 표준안을 공식 제안하고, 관련 전문가의 의견수렴 등의 절차를 밟아 내년 6월에 최종 채택·확정할 계획이라고 5일 밝혔다. 또 이후 이번 표준안의 국제표준화도 추진할 예정이다.
이번 표준안은 한국정보통신기술협회와 한국정보화진흥원이 작년에 마련한 ‘AI 학습용 데이터 구축 및 품질관리 공통기준’에 해외사례 분석, AI 및 품질관리 전문가 자문 등을 보완해 내놓은 것이다.
데이터가 적정한 절차와 요구사항, 규격 등으로 처리되는지에 따라 AI 기술·서비스의 성능이 좌우된다. 하지만 아직 세계적으로 품질 수준이 높지 않은 상황이다. 이를테면 마이크로소프트(MS)나 구글 등이 4~6년 넘게 구축·업데이트해온 유명한 개방 데이터셋의 경우에도 데이터 정확도가 43~83% 수준에 불과하다. 이는 아직 세계적으로 AI 데이터 품질에 대한 체계적 방법론이 정립되지 않은 것이 원인이란 설명이다. 특히, 지난 4월 우리나라가 ‘AI 국제표준화회의’에 AI 데이터(딥러닝) 품질 관련 사항을 신규 과제로 제안해 채택되는 등 이제 막 논의가 시작된 초기 단계이다.
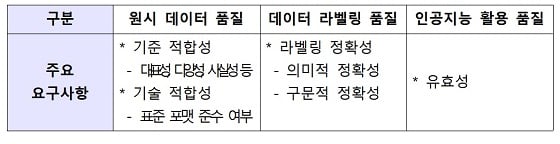 주요 품질 요구사항 품질관리 대상이 되는 데이터 상태에 따라 원시데이터, 데이터 라벨링, 인공지능 활용 품질 요구사항으로 구분/자료=과기정통부
주요 품질 요구사항 품질관리 대상이 되는 데이터 상태에 따라 원시데이터, 데이터 라벨링, 인공지능 활용 품질 요구사항으로 구분/자료=과기정통부구체적으로는 원시데이터 수집단계의 다양성, 사실성 등의 품질 요구사항과 파일 포맷, 해상도 등의 기술 적합성 요구사항, 정제단계의 데이터 중복방지 및 비식별화 조치 요구사항, 가공단계의 객체 분류체계 및 라벨링 규격 요구사항, 품질검수·활용 단계의 유효성 등 검수 요구사항·방법 등이 수록됐다.
 주요 품질 요구사항품질관리가 수행되어야 하는 데이터 구축 단계에 따라 데이터 획득, 정제, 라벨링, 품질검수 및 활용 품질 요구사항으로 구분/자료=과기정통부
주요 품질 요구사항품질관리가 수행되어야 하는 데이터 구축 단계에 따라 데이터 획득, 정제, 라벨링, 품질검수 및 활용 품질 요구사항으로 구분/자료=과기정통부