 /사진제공=NIA
/사진제공=NIA한국지능정보사회진흥원(NIA)은 지난달 말 공개한 '대규모 언어모델 기반의 초거대 AI 도입방향' 보고서를 통해 이 같은 전략을 제시했다.
정부는 지난달 14일 디지털플랫폼정부 구축 청사진을 공개하면서 대국민 서비스에 AI를 접목해 개선하는 방향의 '민간 초거대AI 모델을 활용한 정부 전용 초거대AI' 도입 계획을 제시한 바 있다.
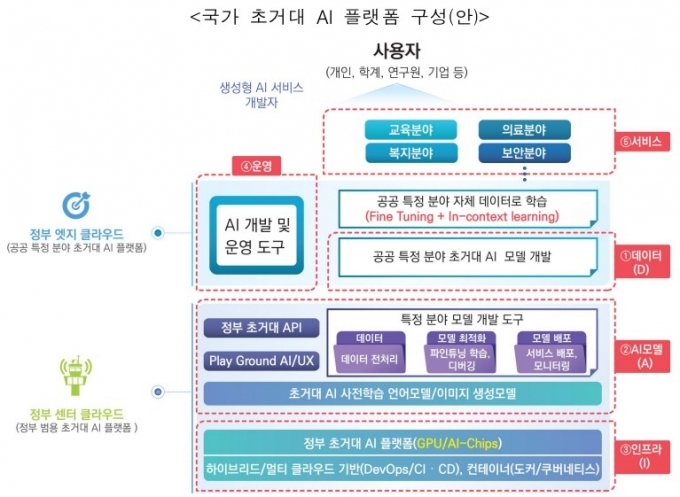
보고서를 작성한 윤창희 NIA 정책본부 AI·미래전략센터 수석연구원은 "하이브리드 전략이 필요하다"고 강조했다. 민간의 개방형 초거대AI 모델을 바탕으로 정부 기반 무료 서비스는 대국민 API(응용프로그램 인터페이스) 형태로 제공하되, 민감정보를 포함한 국가 정보의 경우 '폐쇄형' 정부 서비스를 자체 개발해야 한다는 주장이다.
이에 보고서는 챗GPT 수준의 국가 초거대AI모델을 만들기 위해선 정부·민간의 협업이 필요하다고 강조했다. 우선 민간 기업의 초거대AI(파운데이션 모델)를 활용하는 경우 API가 아닌 공공 클라우드에 직접 설치해야 한다고 강조했다. 민간 클라우드 이용 시 정보 유출 가능성이 커져 공공의 학습이 어려워질 수 있는 만큼, 최소한의 사전·강화 학습이 가능한 용량의 자원을 공공 클라우드에 사전 확보해야 한다는 주장이다.
아울러 GovGPT와 같은 폐쇄형 모델의 경우 대외비 또는 민감정보가 포함된 문서를 포함해 학습데이터를 구축하되, 외부기관에 위탁하기보다는 공공 영역에서 현장에 맞는 학습데이터를 개발·진행해야 한다고 제안했다. 아울러 거대언어모델(LLM) 구축을 위해 대규모 GPU, AI반도체 등의 자원이 필요한 만큼 공공 클라우드 환경에서 관련 환경을 사전에 구축하고, 국내외 LLM 기업의 사전 구축된 데이터를 확보할 필요가 있다고 강조했다.
이 시각 인기 뉴스
윤 수석연구원은 "디지털플랫폼정부 구축이 본격화되는 과정에서 구현되는 초거대AI 서비스에서 각종 오류가 발생할 경우, 사회적 문제로 번질 수 있다"며 "중장기적으로 공공 부문의 초거대AI 서비스는 정부가 플랫폼을 구축해 자체적으로 관리할 수 있는 형태가 돼야 한다"고 강조했다.